Well, that's the point. Pershing doesn't have superior AI in tests.
https://youtu.be/ZeR8ZjeV_uM
https://youtu.be/fJ0hfawIg2A
If you think I have done something wrong here, you are more than welcome to provide more tests here. After all, sample size is too small. But we can clearly see that AI is even(or worse) to the Tiger.
Just to take the sample size issue up once more, since I feel it's quite crucial to understand what implications the limited number of repetitions in any test regarding these hugely RNG-based results can have.
I've taken a look in the data log for the simulations posted some days ago in the State of Heavies thread and calculated the T2K values using the results from the first 3, 5, 10, ..., 1000 iterations of the same test (similar to the picture below, but assuming a target size of 0.5 for each model) for the Tiger and Pershing.
If you take a look at how the averages vary even for relatively large sample sets of 100 or more repetitions, it becomes pretty clear why in-game tests, as important they undoubtedly are, can be quite deceiving at times. Though all results point into a certain direction (Pershing being a bit faster than the Tiger), the differences can be rather huge if you take only a handful of tests into consideration.
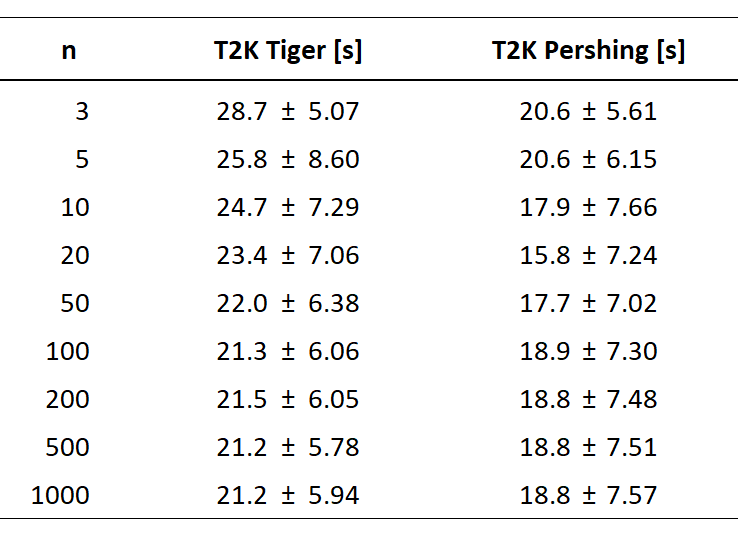
Again, this is in no way meant to devalue the intent and effort put into conducting the tests in the video. It merely shows that for problems seemingly as simple as "how long does it take tank A and B to nuke the target squad on average", it is next to impossible to perform enough in-game test to get to a robust and reliable conclusion.



















")



 cblanco ★
cblanco ★  보드카 중대
보드카 중대  VonManteuffel
VonManteuffel  Heartless Jäger
Heartless Jäger 